引子
刚才下班回家路上,无意中听到大街上放的歌,歌词有这幺一句:“毡房外又有驼铃声声响起,我知道那一定不是你”,这一句我似乎听懂了歌者的魂牵梦绕和绝望,如果在十年前我大概只能感受出悠扬的声调里溢位的悲凉吧,
在作业上,我没有十年的时间来把思考能力上升一个等级,对于一个问题,需要在很短的时间反复思考,深层次的弄懂,懂得,有三个初级境界,对应三个方法:
1>字面理解-what、why、how
2>前因后果-5why
3>选择最优-SMART
想了解what、why、how黄金圈法则或者5why分析法可参考我之前的文章:《代码荣辱观-以运用风格为荣,以随意编码为耻》;想了解SMART原则可参考我之前的文章:《知名互联网公司需要什么样的人才》,
回到主线:为什么是初级境界?我自己也不知道更高级别的境界是有什么,因为自己境界没有达到,但是至少有:刻入骨髓 这一境界,
举个例子:十二年前,有次在大街上走,我走过一个【北京银行】的大门,银行二楼的玻璃哗啦啦掉下来,我知道身后有危险,有很多玻璃落到了距离我身后不到十公分的地方,我当时很镇定的继续向前走,等过了危险区,我很想神经质的大叫,因为走路时再多犹豫2秒,可能脑袋上被扎的全是玻璃,所以走路时时时刻刻都会想着离楼房远一些,并且好像感受到了自己脑袋被玻璃扎,我理解这可以算作把楼房玻璃很危险的理解刻入骨髓,
字面理解
今天举的这个例子纯粹是技术问题,终于不需要用蹩脚的比喻把事情描述的更难理解来达到脱敏的效果,
what
我们采用的是dubbo服务,这是个稳定成熟的RPC框架,但是我们在某些应用中会发现,只要这个应用一发布(或者重启),就会出现请求超时的问题,如下图所示: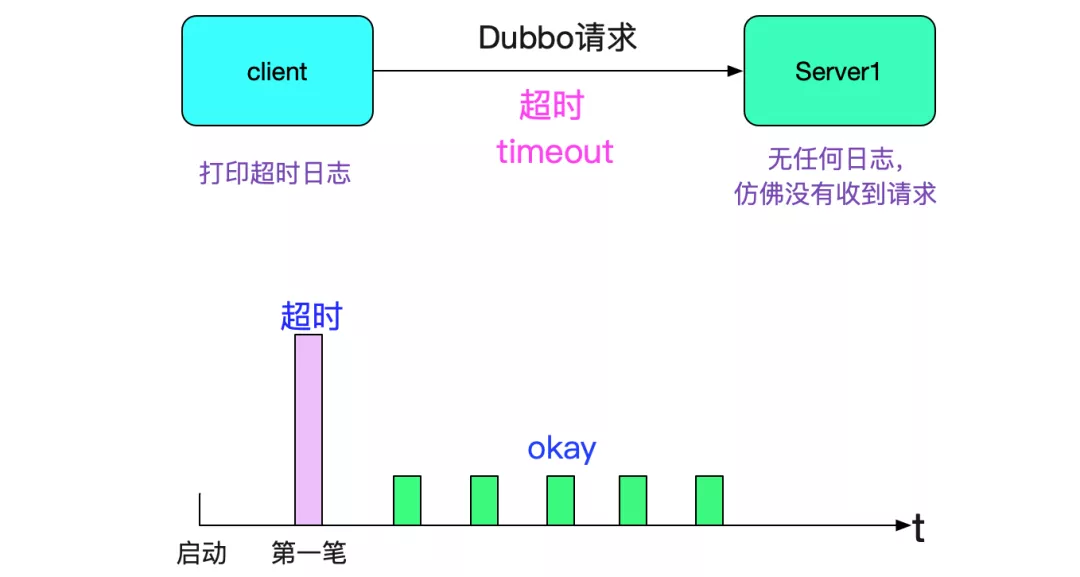
而且都是第一笔请求会报错,之后就再也没有问题了,
why
我当时很快就定位了问题,因为在内网wiki上、技术博客上,很多人都写了这个坑,所以不讲排查思路了,直接讲结论:
在server端连接数过多, linux系统有个连接队列溢位了,溢位的连接被丢弃,但是client端不知道,仍然给此server发送讯息,连接没有建立自然发送不成功,client发第一笔讯息超时,相当于探活失败,client端于是重新建立连接,连接成功建立后开始正常的通信,所以后面都成功了,
how
怎么来解决这个问题呢?四个思路,
第一个是队列溢位了,那就说明队列太小,可以把队列值改大,dubbo使用的是一个写死的默认值:50,可以修改dubbo原始码把值改大或者干脆动态获取队列值,
第二个是队列数不变,实际连接数减少,减少server端的连接方,比如有些client端其实没有实际业务呼叫这个server端了,就双方聊聊把无用的依赖去掉,
第三个是可以让服务端在丢弃连接的同时给client端通知一下,linux有个系统自变量/proc/sys/net/ipv4/tcp_abort_on_overflow,默认为0,不会给client端发通知,但是设定为1时会给server端发一个reset请求,客户端收到会重连,
第四个是让client端定时心跳探测,探测发现超时了马上重连,超时的那笔只是探测请求,不影响业务,

前因后果
作为软件工程师,重要的一个软素质是批判性思维,多问几个问题,找到答案,理解就能更进一步,
Q1: 提到溢位的队列到底是什么队列?
A: 下图是TCP连接三次握手的示意图,
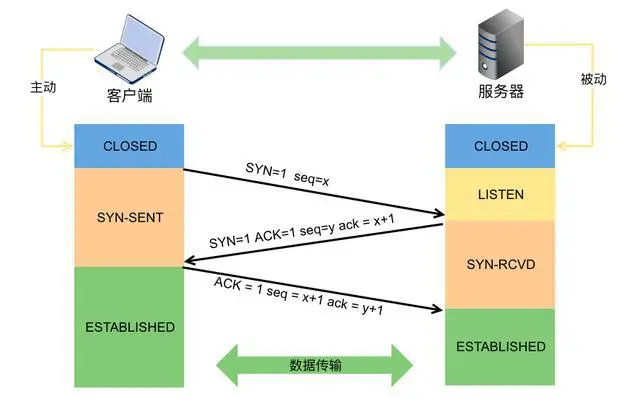
一次握手:
一开始client端和server端都处于closed状态(未建立连接状态),client端主动向server端发起syn请求建立连接请求,server端收到后将与client端的连接设定为listen状态(半连接状态),问题来了,server端怎么保存与client端的状态呢?总需要有地方存呀,存的地方就是队列,连接队列又叫backlog队列,到这里,server端与client端的半连接建立了,这里的backlog队列也叫半连接队列,
二次握手:
server端回传ack应答+syn请求给client,意思是:ack我收到了你的请求,syn你收到我的了没?client端收到server端回应,将自己的状态设定为established状态(连接状态),
三次握手:
client向server端发送一个ack回应,告诉server端收到,然后server端收到后将与client端的连接设定为established状态(全连接状态),同样,全连接状态在server端也需要一个backlog队列存盘,这里的backlog队列也叫全连接队列,
Q2: backlog队列到底是全连接队列还是半连接队列?
A: 这个问题让我想起别的事情,我大学是东北大学,有次看到校内论坛上有个帖子:“东北大学和东南大学谁更有资格叫东大?”最终没啥结论,东北大学内网再论证自己该叫东大,东南大学内网肯定不认,
但是backlog的问题还是有达成共识的可能的,backlog其实是一个连接队列,在Linux内核2.2之前,backlog包括半连接状态和全连接状态两种队列,在Linux内核2.2之后,分离为两个backlog来分别限制半连接(SYN_RCVD状态)队列大小和全连接(ESTABLISHED状态)队列大小,
半连接队列:
队列长度由/proc/sys/net/ipv4/tcp_max_syn_backlog指定,默认为2048,
全连接队列:
队列长度由/proc/sys/net/core/somaxconn和使用listen函式时传入的自变量,二者取最小值,默认为128,
在Linux内核2.4.25之前,是写死在代码常量 SOMAXCONN ,在Linux内核2.4.25之后,在组态档/proc/sys/net/core/somaxconn中直接修改,或者在 /etc/sysctl.conf 中配置 net.core.somaxconn = 128 ,
想到这里我恍然大悟,东北大学、东方大学、东南大学在自己的地盘都有资格简称东大(这里讲这个插曲是为了澄清一件事情:我昨天下午4点发的文章里标题是一个北大妹子,那篇文章是帮朋友的忙,北大妹子不是我,我是东大妹子),
Q3: 到底是全连接队列还是半连接队列溢位导致了超时?
A: server端与client端进行二次握手的前提是server端认为自己与client建立连接是没有任何问题的,如果server端半连接队列溢位了,自己这边都没有处于半连接状态,自然不会发送ack+syn给client端,client端做的应该是重新尝试建立连接,不是发送资料,请求会发送到已经建立好连接的server端(server端是多机器多活部署的)不会造成请求超时,
而二次握手一旦完成,进行三次握手时,如果全连接队列已满,服务器收到客户端发来的ACK, 不会将该连接的状态从SYN_RCVD变为ESTABLISHED,但是客户端已经认为连接建立好了开始发送资料了,这时候是有可能造成超时的,
Q4: 全连接队列满了之后server端是怎么处理的呢?
当全连接队列已满时,则根据 tcp_abort_on_overflow 的值来执行相应动作,
tcp_abort_on_overflow = 0 处理:
则服务器建立该连接的定时器,这个定时器是一个服务器的规则是从新发送syn+ack的时间间隔成倍的增加,比如从新了第二次握手,进行了5次,这五次的时间分别是 1s, 2s,4s,8s,16s,这种倍数规则叫“二进制指数退让”(binary exponential backoff),
给客户端定时从新发回SYN+ACK即重新进行第二次握手,(如果客户端设定的超时时间比较短就很容易出现例外)服务器重新进行第二次握手的次数由/proc/sys/net/ipv4/tcp_synack_retries 这个linux系统自变量决定,
tcp_abort_on_overflow = 1 处理:
当 tcp_abort_on_overflow 等于1 时,发送一个reset请求重置连接,客户端收到可以尝试再次从第一次握手开始建立连接或者其他处理,
Q5: 怎么验证确实是backlog队列溢位呢?
ss 是 Socket Statistics 的缩写,ss 命令可以用来获取 socket 统计信息,ss -l 是显示listen状态的资料,如下所示:
[root@localhost ~]# ss -lState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:http *:*LISTEN 0 128 :::ssh :::*LISTEN 0 128 *:ssh *:*LISTEN 0 100 ::1:smtp :::*LISTEN 0 100 127.0.0.1:smtp *:*
在LISTEN状态,其中 Send-Q 即为全连接队列的最大值,Recv-Q 则表示全连接队列中等待被server段处理的数量,数量为0,说明处理能力很够;Send-Q =Recv-Q ,满了,再来就丢弃掉了,
但是这是一个实时的资料,一段时间有拥塞,过一会儿就好了怎么查呢?
可以使用netstat -s 可以查看被全连接队列丢弃的资料,
[root@localhost ~]# netstat -s | grep "times the listen queue of a socket overflowed"35552 times the listen queue of a socket overflowed
补充说明: 半连接队列很多文章叫做SYN QUEUE队列,全连接队列很多文章叫做ACCEPT QUEUE队列,这是一些研究linux原始码的同学根据原始码的命名来叫的,

选择最优
马云说:“选择比努力重要” ,懂得三境界,第三境界的重点不是懂,而是得,最终要根据懂了的内容决策出最优方案,
除了字面理解里提到的四种思路,前因后果里还提到了重新进行第二次握手的次数由/proc/sys/net/ipv4/tcp_synack_retries 这个linux系统自变量决定,
分别来分析一下各个方案的可行性和优缺点:
方案1:把队列值调大
这个队列值是指全连接队列,调大之后,client端的二次握手就在这个队列里排队等待server端真正建立连接,假设队列值调到上限65535,第65535号请求在排队的程序,client端是established状态,资料可能会发送过来,服务端还没有established状态,还不能处理,
到什么时候能处理呢?65535个请求全部处理完需要13s的样子,对一般的服务来说妥妥的超时,所以nginx和redis都是使用的511,让回应时间在100ms内完成,
方案2:减少连接数
只要能减少的下来,这是理想的法子,现在server端都过载了,可想而知,接入的client端不再少数,推动他们一个个去梳理和改造,就算大家执行力很强,把改下的下了,可想而知,废弃的也一般不会有多少,不展开了啊,现在已经三千多字了,争取五千字内结束,
还有没有别的方法减少连接数呢?最简单的就是使用分治法,
划分子集
跟同事讨论请教的时候,他给我提供了一个划分子集的思路,让client端只和server端一部分服务器建立连接,有两种分配谁跟谁连接的算法,一个是随机算法,但是server端服务器我最多见过几千台组成一个集群的,对随机(虽然连接数是服务器台数的n倍)来说,样本是很少的,会很不均匀;另外一个是确定性算法,思路也很简单,连接的client端及数量是确定的,那就排个序,按照server端数量分配一下,这样连接数是均匀的,但是就没办法做到请求级别的流量均匀,
粘滞连接
尽可能让客户端总是向同一提供者发起呼叫,除非该提供者挂了,再连另一台,<dubbo:protocol name="dubbo" sticky="true" />,如果每个client端都只和一个server端建立连接,那server端压力就是原来的(1/机器台数),不够加机器就行了,横向可扩展,

这种做法最大的问题是高可用和并发请求的问题,对于可用性要求不高、请求量不高的服务(比如后台定时任务定时拉取可重试)其实是可以用的,但是这需要client端的自觉性,而对维护这个client端的人员来讲,他们自身是没有好处的,因为原本也就是只是重启时发生一次超时嘛,所以客户端在可以的情况下愿不愿意这样做就看格局了,
方案3:服务端通知
服务端通知上面前因后果中有提到可以设定
/proc/sys/net/ipv4/tcp_synack_retries
重新进行几次进行第二次握手,但是这个阶段,client端可能会发资料包过来造成超时;另外,可以设定
/proc/sys/net/ipv4/tcp_abort_on_overflow=1
整个握手直接断掉,client端是closed状态,它会找其他established状态的连接进行资料包发送,不会造成超时,事实上,调研了一些大厂,
tcp_abort_on_overflow=1是作为默认配置的,
方案4:客户端探测
客户端探测想自己做的话比较麻烦,比如说把,客户端调了n个服务,每个服务建立了n个连接,资源开销大,还必须要复用这些已经建立的连接,复杂度高,
其实provider 和consumer 有双向心跳(探测)的,那为什么没检测出并进行重连?
这个首先面临的问题:client端认为连接成功了,但server端认为没有成功,那么server端 是不会发送心跳给 client端的,
client端是不是应该发心跳给server端呢?是的,原来使用dubbo2.5.3版本时3分钟client端会发送一个探测,之后把问题连接closed掉,只是dubbo 2.6.9使用了netty4,他们强强联手搞出来一个bug,探测机制楞没生效!
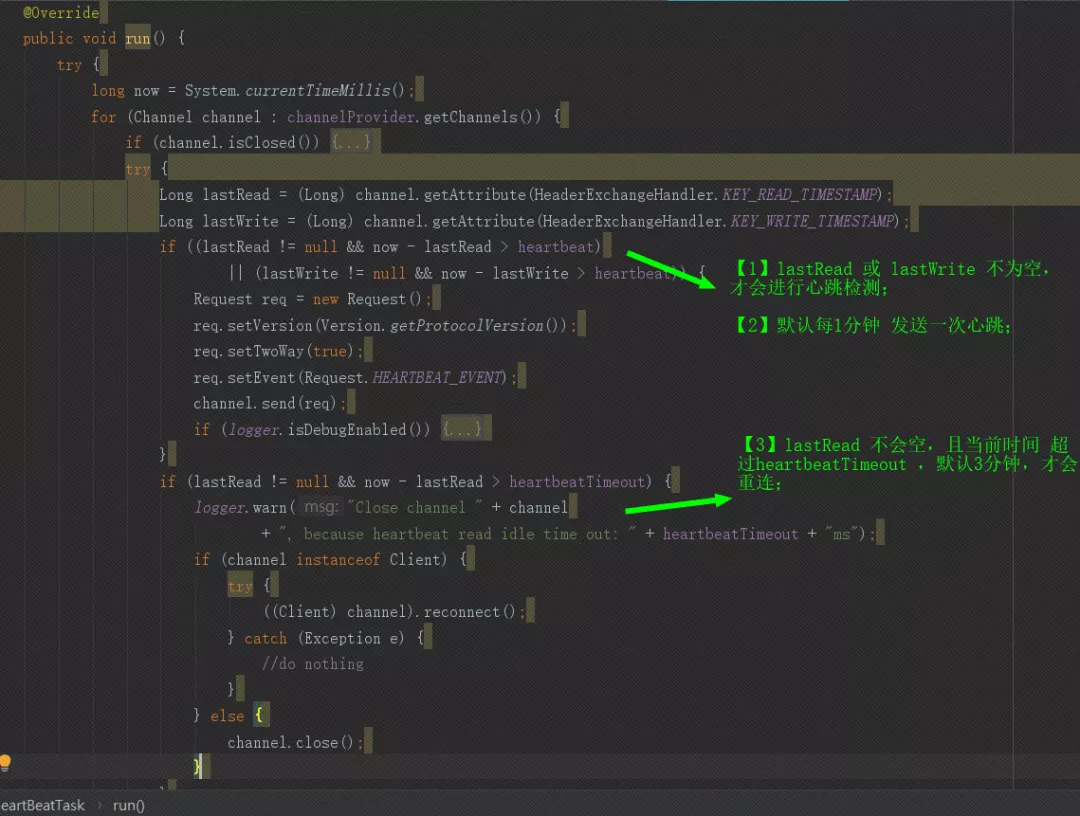
心跳有个条件,就是lastRead 和 lastWrite 不为空,那就需要看哪里设定了这两个自变量,通过代码查到client端连接成功和server端连接成功的时候都会设定,这里只考虑client端情况,对比netty3发现netty4里少了
NettyServerHandler的handler链处理,这个handler链处理就是用来初始化那两个值的,
除了改client端原始码,有没有别的方法让client端探测生效呢?其实什么都不用TCP就有keepalive(探活)机制,默认是7200秒,也就是2小时,可以修改:
/proc/sys/net/ipv4/tcp_keepalive_time
单位是秒
好了,解决问题的方法就讲到这里,完结撒花~~
咦,说好的SMART原则呢?
S代表具体的(Specific)
M代表可衡量的(Measurable)
A代表可达到的(Attainable)
R代表与最终目标是相关的(Relevant)
T代表有明确的截止期限(Time-bound)
编程一生,公众号:编程一生知名互联网公司需要什么样的人才
方案这幺多,哪种是最好的呢?看场景,方案4提到了问题其实是开源组件有bug导致,但改开源组件,看公司规划、开源社区支持,A可行性上有制约;
方案2涉及很多整改和推动,T时效上有制约,方案虽多,排除法排除一下能剩下一个就不错了,








0 评论